Browser automation and web scraping
This scraper, built with Python and Playwright, automatically completes the Hims medical intake form for weight loss treatment and records which medication the website recommends based on your entries. It can run repeatedly with different patient information in order to gather data on what treatments Hims recommends for different types of people.
Mapping and spatial analysis
This map shows crimes that occurred near selected subsidized housing developments in Toledo, Ohio. I used QGIS to create half-mile buffer zones around specific addresses and spatially join them with crime data from the Toledo Police Department, creating a new dataset that distinguishes between crimes that happened inside and outside the buffer zones. I then imported the map layers into Mapbox and styled them.


Extracting data from PDFs
I took a batch of messy PDF files containing accident investigation reports for offshore oil and gas facilities, parsed them with pdfplumber, and transformed the information into an easy-to-analyze database.
Undocumented APIs
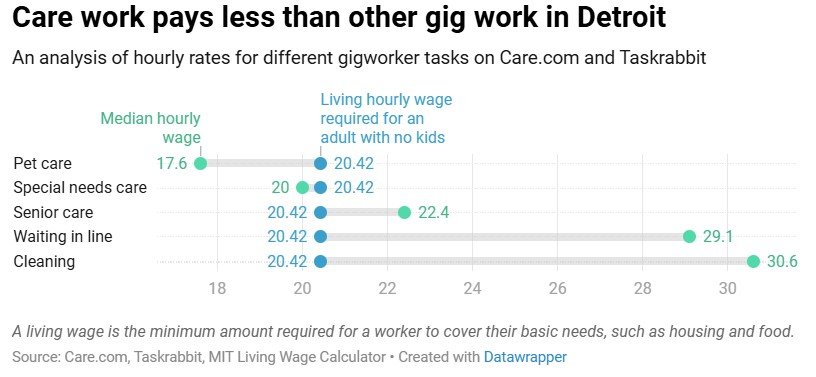
This project used undocumented APIs on taskrabbit.com and care.com to gather data about the hourly rates charged by different gig workers. I built programs that used custom inputs (e.g. the type of gig work or the city) to call the APIs, clean the data, and organize it into an easily useable database.

Building and analyzing datasets
I extracted a demographically equal random sample from the PERSUADE 2.0 dataset, which is used to train AI systems to grade student writing, and ran the essays through Grammarly and Writable, two popular grading engines. Using Pandas and Vega-Altair, I analyzed the resulting grades and demonstrated that the two AI models often disagreed with human graders and each other, giving very different scores to the same essays,